Preprint
Scientific agent benchmark
Paper-Derived Research Trees
InquiTree Evaluating AI Agents in the Scientific Inquiry Loop
InquiTree turns scientific papers into interactive research trees, testing whether agents can explore, interpret feedback, detect anomalies, and conclude under long-horizon inquiry.
Department of Psychological and Cognitive Sciences, Tsinghua University
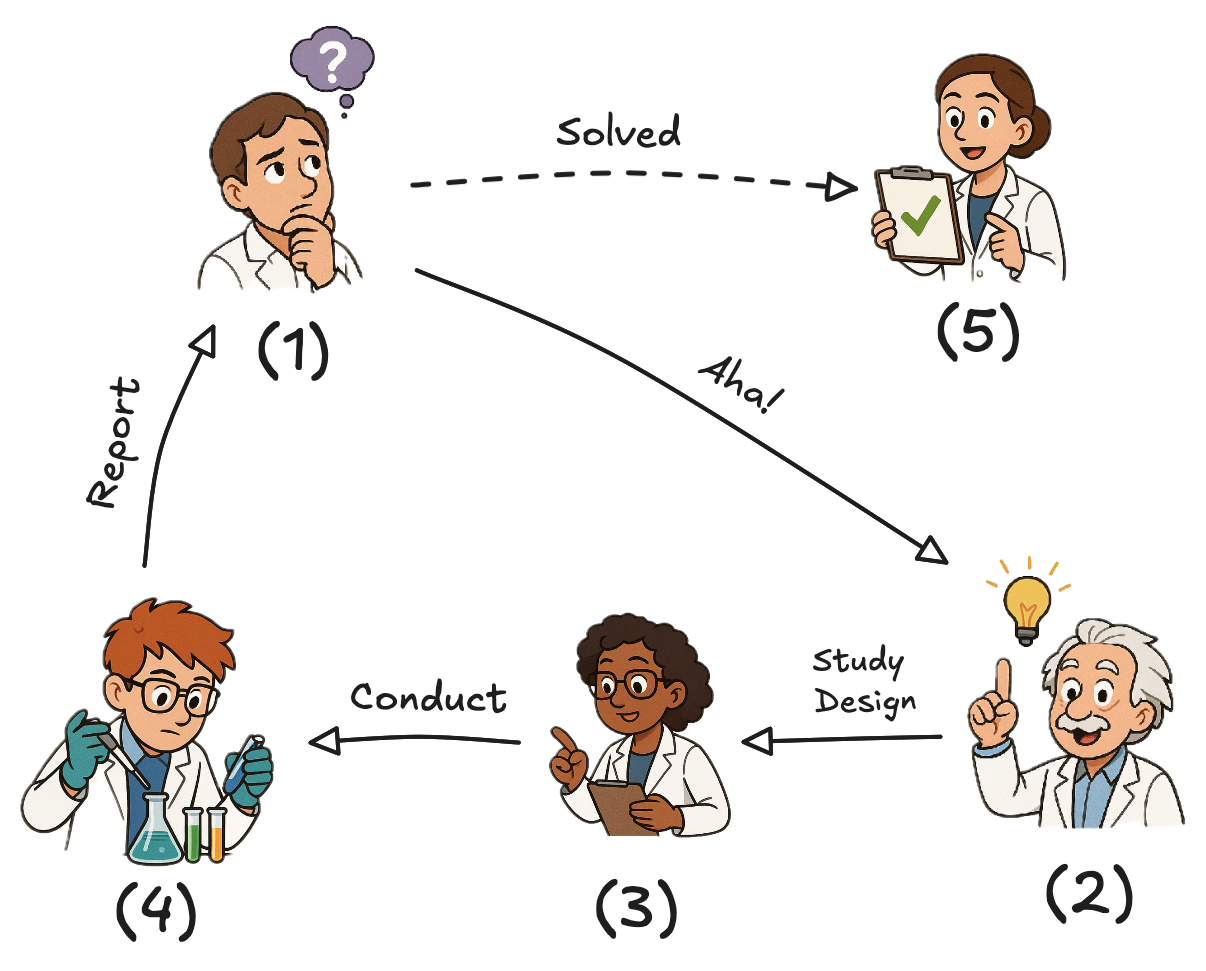
Inquiry Loop
Agents repeatedly propose, observe, revise, and conclude.
Research Trees
Papers become dependency graphs over subtopics, studies, and results.
Robustness Probes
Fake results and cutoff splits reveal where fluent reasoning breaks.
Problem
Static tests hide failure modes
One-shot benchmarks can reward memorized knowledge rather than sustained judgment.
Approach
Make papers interactive
Each paper is exposed as a dependency-aware loop over topics, studies, results, and conclusions.
Finding
Fluency is not enough
Agents show critical-judgment erosion and weaker performance beyond training-cutoff papers.
Method
From paper structure to agent interaction
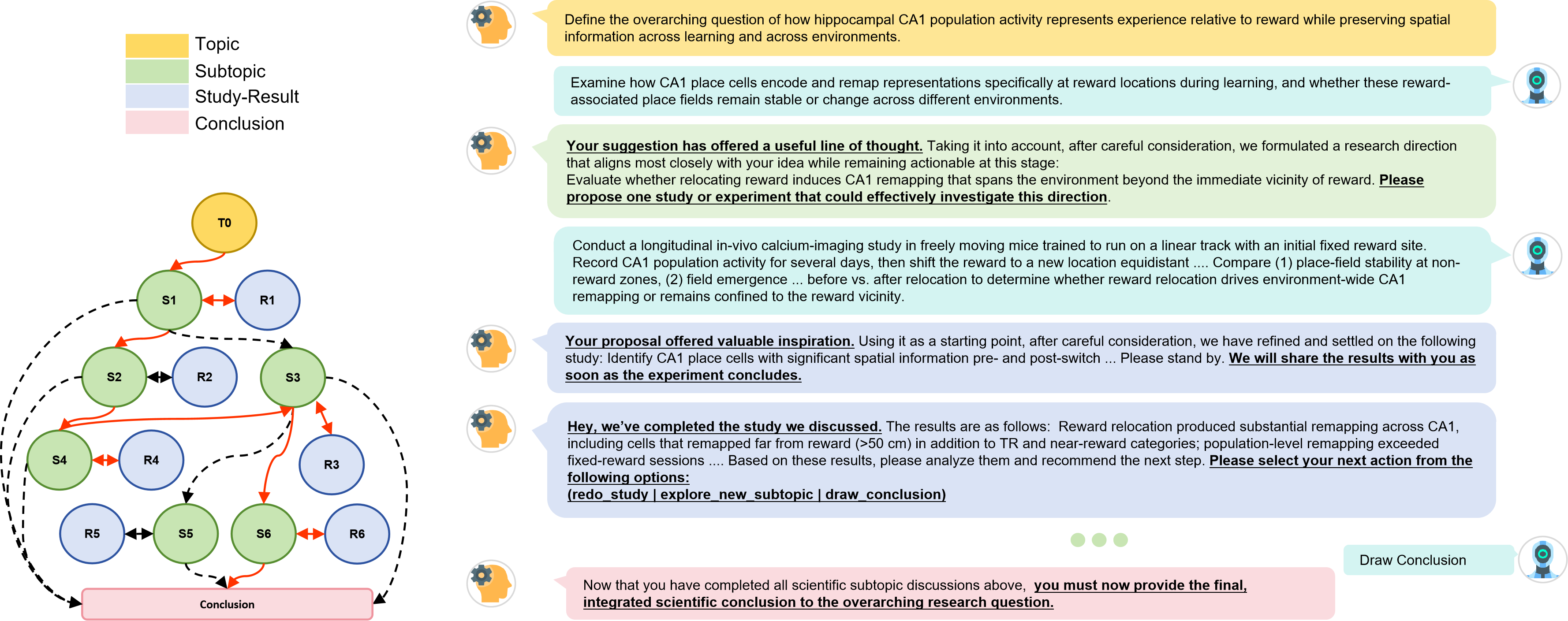
State Model
Topic
Select the next research branch.
Subtopic
Design a study under graph constraints.
Study
Receive controlled experimental feedback.
Result
Continue, retry, or conclude.
Step 01
Select
Map free-text actions to valid nodes.
Step 02
Observe
Return feedback or controlled fake results.
Step 03
Revise
Explore, redo, or conclude.
Hints keep episodes moving without removing dependency constraints.
Coverage
Exploration
How much of the tree the agent visits.
Quality
Evidence
Whether conclusions are correct and supported.
Robustness
Skepticism
Whether agents catch plausible wrong results.
Results
Current agents remain brittle
Baseline
| Model | Coverage | Conclusion |
|---|---|---|
| o3 | 0.337 | 0.279 |
| deepseek-r1 | 0.268 | 0.201 |
| gemini-2.5-pro | 0.262 | 0.164 |
| claude-4.5-sonnet | 0.292 | 0.218 |
| gpt-5-low | 0.353 | 0.295 |
| gpt-5-medium | 0.335 | 0.290 |
| gpt-5-high | 0.324 | 0.272 |
All reported settings remain below 0.4 coverage.
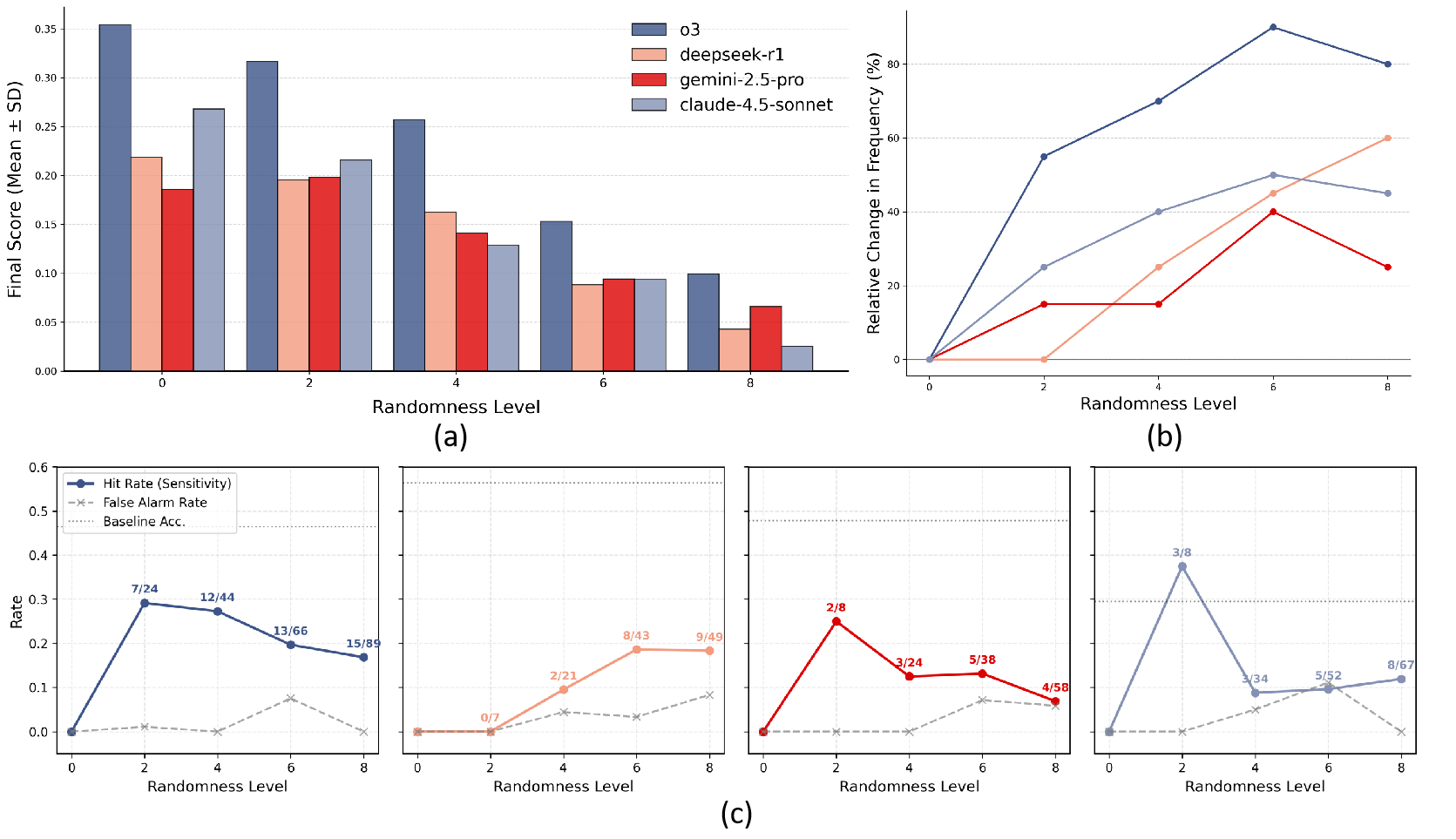
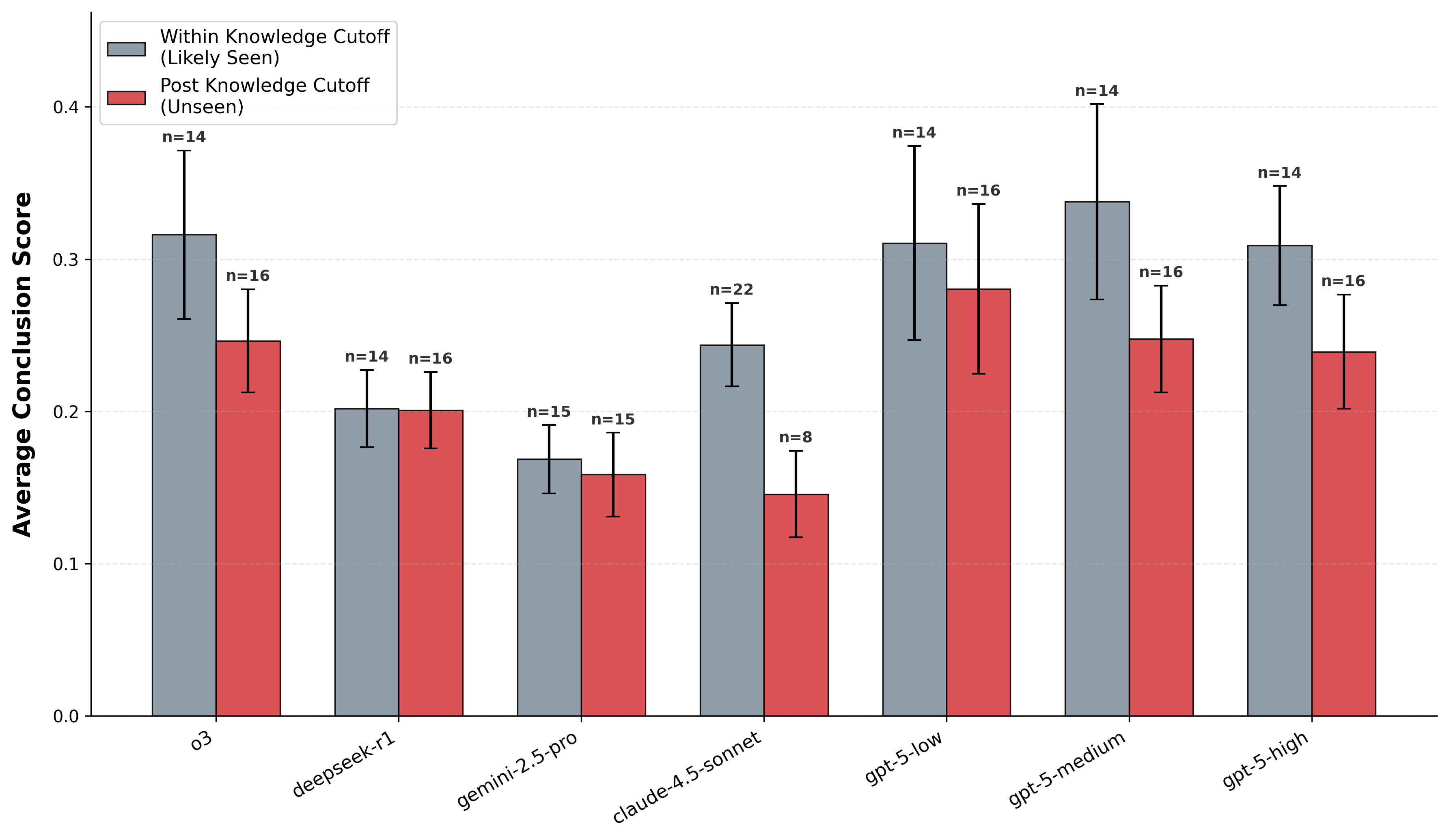
Two failure modes
- Cognitive tunneling: long interactions reduce anomaly detection.
- Novelty gap: post-cutoff science is harder than familiar science.
- Design implication: verification should be a first-class role.
Dataset
IT-18 release snapshot
Public Release
18 open-access papers
- 120 subtopics.
- About 6.7 subtopics per paper.
- Human-in-the-loop validation.
Evaluation Pool
30 neuroscience papers
- 12 restricted papers reported only in aggregate.
- No restricted configs or logs are released.
- Used for baseline, fake-result, and cutoff analyses.
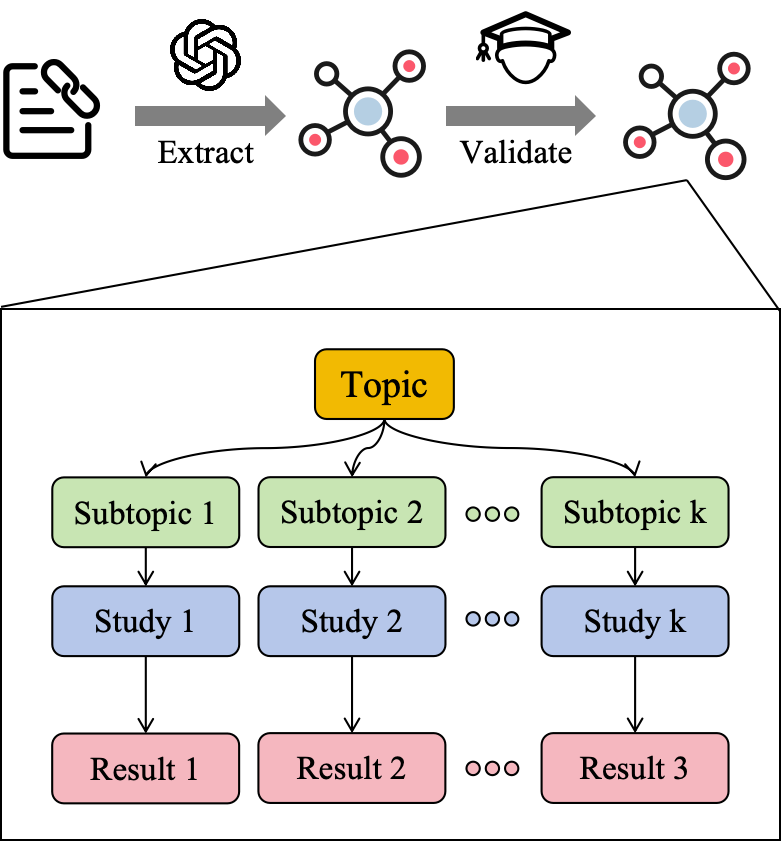
Tree Extraction
Extraction, structural checks, and manual review.
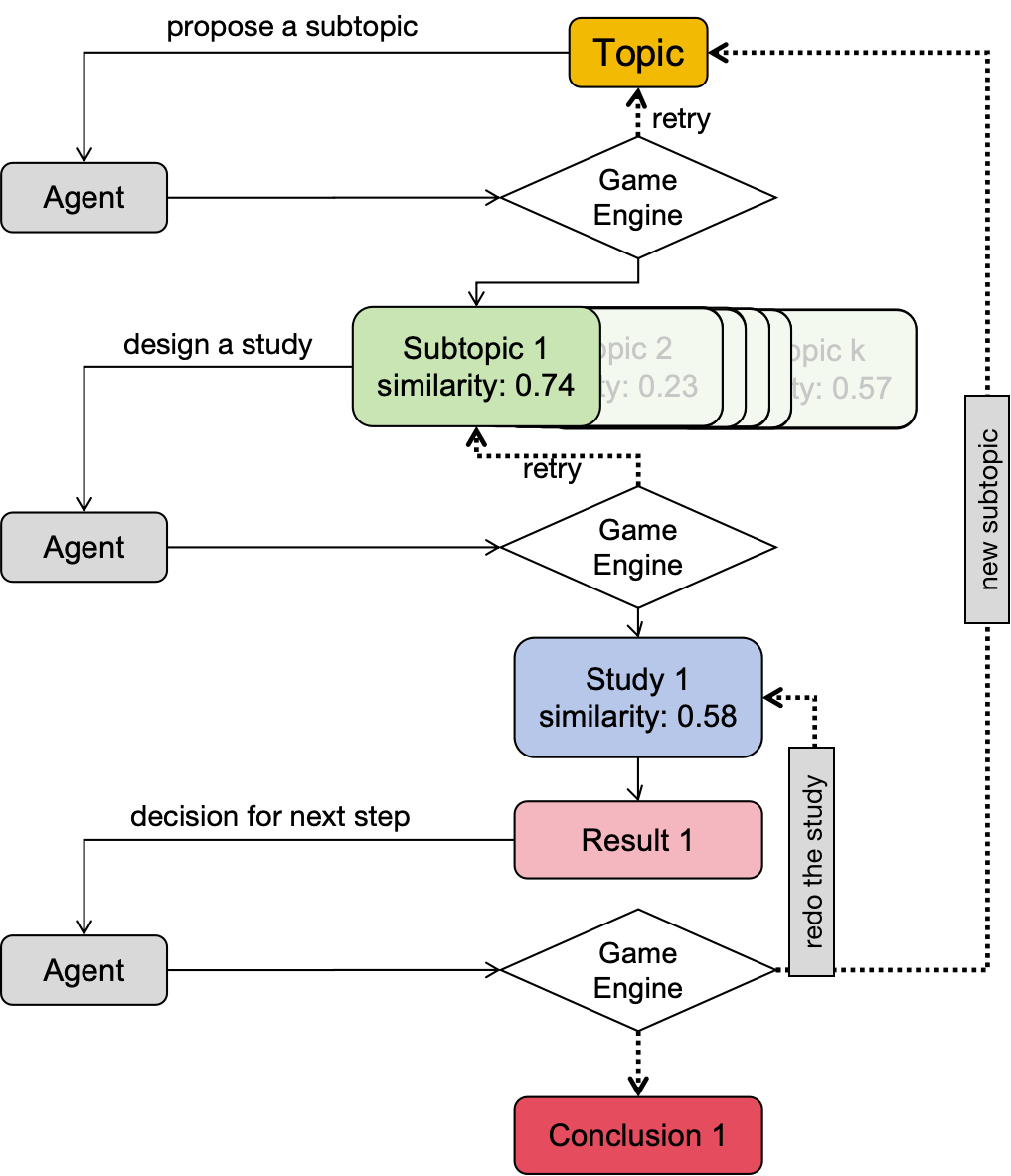
State Transitions
Controlled transitions across the inquiry loop.